Wer regelmäßig mit Codex arbeitet, kennt das Problem: Der KI-Assistent erstellt neue Dateien, verändert bestehende, und plötzlich steht man vor einem riesigen Pull Request. Natürlich möchte man die Änderungen ausprobieren – aber ohne Angst, den eigenen Code unwiederbringlich zu zerstören. ...
In modernen Deployment-Workflows ist es unabdingbar, automatisierte Prozesse sicher zu betreiben. Eine bewährte Methode ist die Verwendung eines dedizierten SSH-Deploy-Users, um die Kommunikation zwischen deinem Server und GitHub abzusichern. In diesem Artikel zeige ich dir Schritt für Schritt, wie du ...

Linux bietet eine Vielzahl leistungsfähiger Tools, die dir den Alltag in der Systemverwaltung und -entwicklung erleichtern. In diesem Artikel stellen wir dir eine Basis-Werkzeugkiste vor, die sowohl für Einsteiger als auch für fortgeschrittene Nutzer unverzichtbar ist. Ich erkläre, was die ...
Beim Arbeiten mit Git kann es schnell passieren, dass fehlerhafter oder unsauberer Code in ein Repository gelangt. Um dies zu verhindern, können Pre-Commit-Hooks eingesetzt werden, die den Code automatisch vor jedem Commit prüfen. In diesem Artikel zeige ich, wie du ...
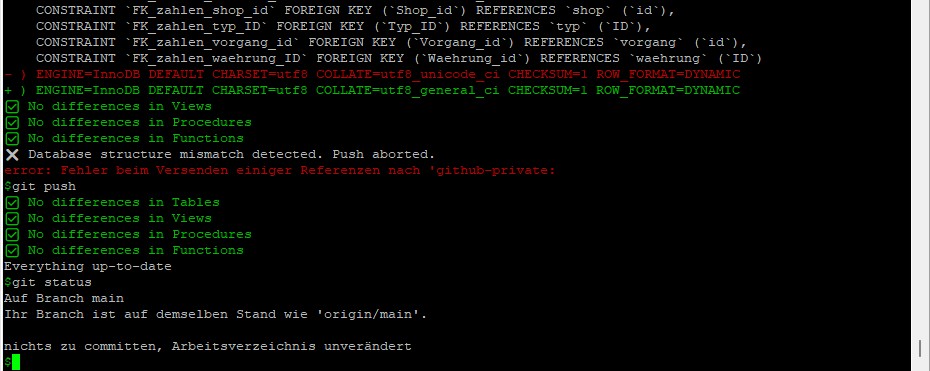
In vielen Softwareprojekten arbeiten lokale Entwicklungs- und Produktionsdatenbanken unabhängig voneinander. Doch was passiert, wenn sich die Tabellenstrukturen ungewollt unterscheiden? Ein fehlendes Feld in der Produktion kann schnell zu unerwarteten Fehlern führen. Um das zu verhindern, habe ich ein PHP-Skript entwickelt, ...
